Learning Next Action Predictors from
Human-Computer Interaction
1Stanford University 2Hasso Plattner Institute 3New York University
What Will You Do Next?
Language models today are hopelessly restricted to seeing us through a narrow keyhole. They see our prompts, and they construct memories to make sense of them. But they know nothing of what brought us to them in the first place. Truly context-aware AIs should understand us deeply: what problems we're solving, what constraints we face, and how we act in the world.
What if models could instead predict what we'll do next on our computers to help proactively? We formalize this as next action prediction (NAP): given a sequence of a user's multimodal interactions with a computer (screenshots, keystrokes, clicks), predict their next action. For example, if a researcher reads paper reviews, a good predictor should reason over this and over the user's past habits to predict they will check experiments on Weights & Biases, then message coauthors on Slack to divide up revisions.
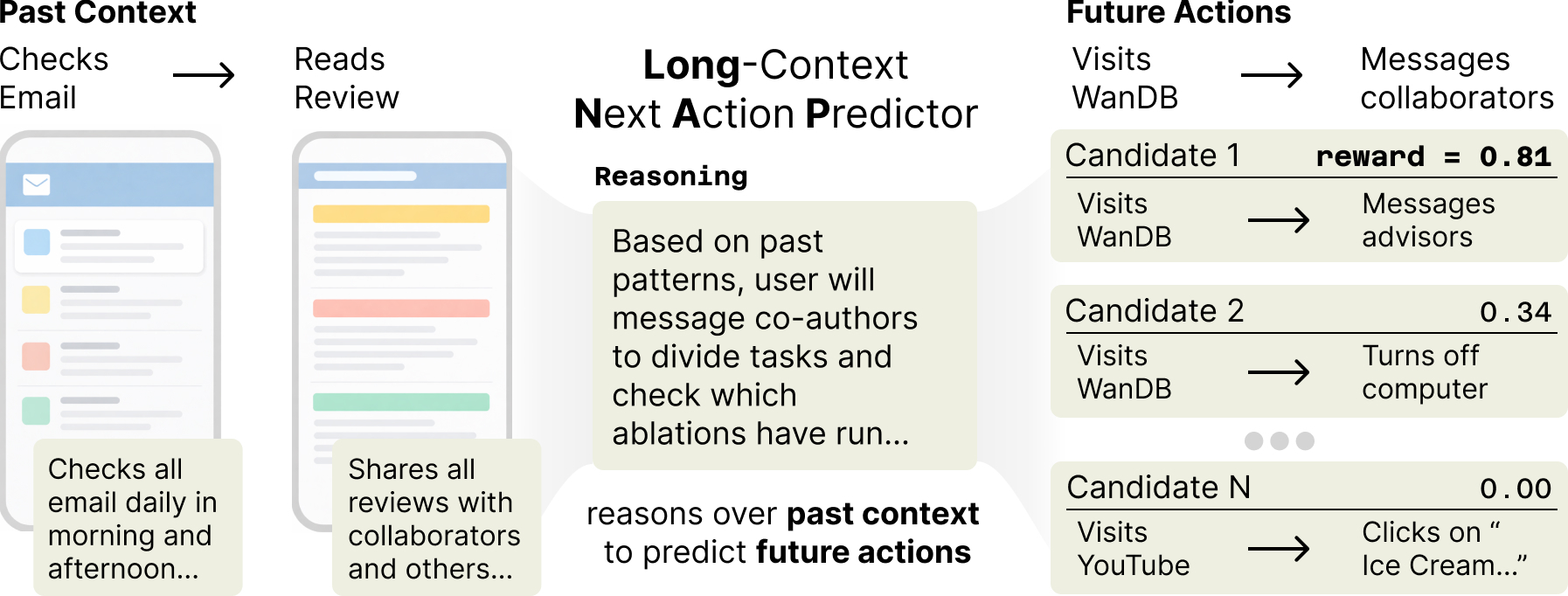
We make progress on two fronts. NAPSack passively collects and labels interaction data at scale. LongNAP combines parametric and in-context learning, trained end-to-end to retrieve relevant past reasoning and predict future actions. The temporal structure of behavior provides a natural training signal: just wait and see what the user actually does.
Labeling Interaction Data with NAPsack
NAPSack is a lightweight, passive tool for collecting labeled interaction data at scale. It continuously records screenshots, groups interactions into bursts of adjacent events, compresses by saving frames only when a user interacts with their computer (reducing storage by approximately 70% without compromising quality), and annotates the resulting records with a VLM. We apply NAPSack to the Screenomics dataset, labeling over 360K actions across a month of continuous phone usage from 20 users (1.8K hours of screen time). Below, watch a labeled session play back.
Labeled Actions
Reason, Retrieve, and Predict with LongNAP
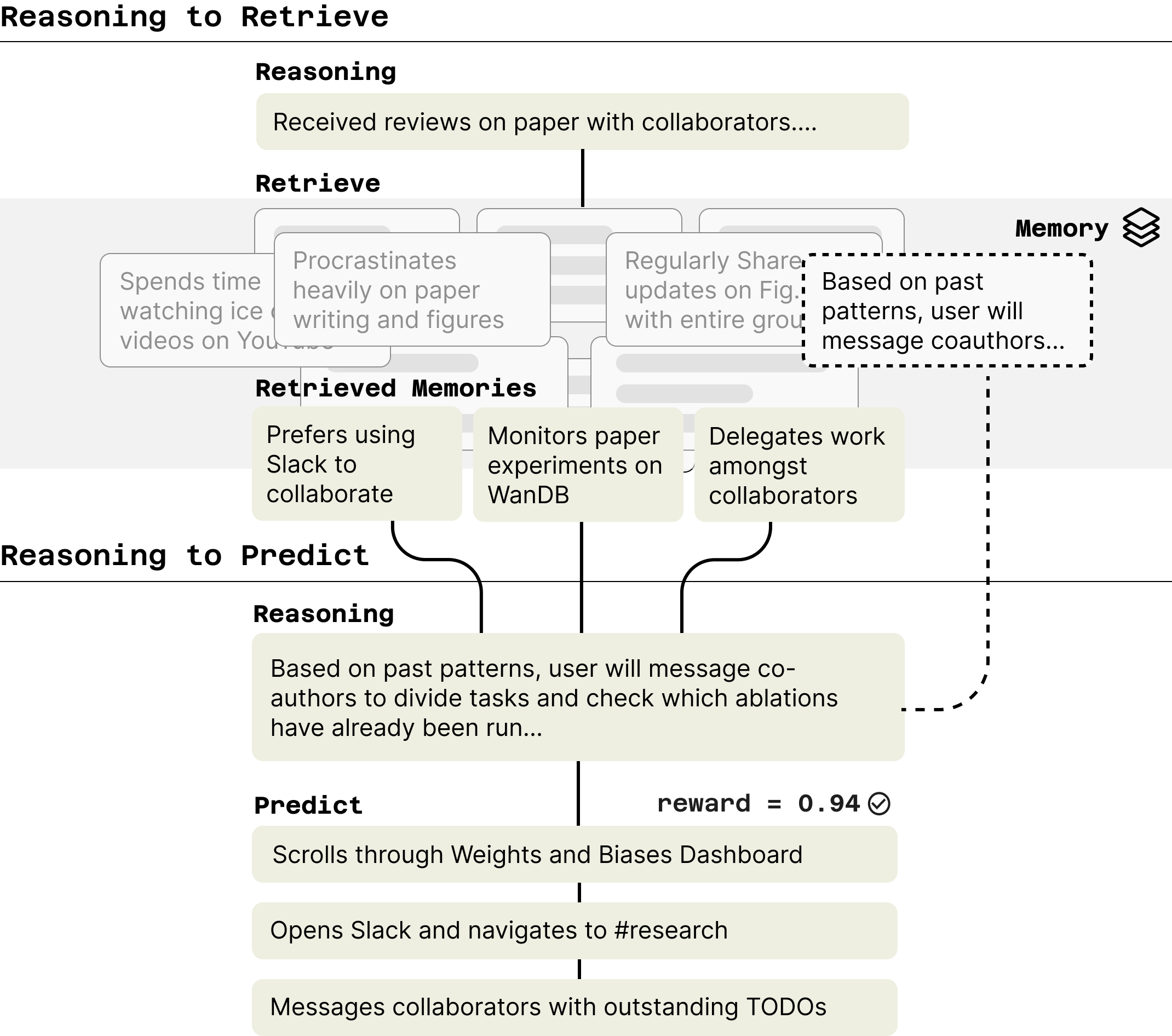
Rather than relying solely on parametric or in-context learning, we train models that learn to retrieve relevant past reasoning and observations into context. We instantiate this in LongNAP, a two-phase model trained end-to-end via policy gradients.
In the first phase, LongNAP reasons to retrieve: the model generates a chain-of-thought, then uses it to query a memory of past observations via BM25. In the second phase, LongNAP reasons to predict: integrating retrieved traces to refine its reasoning and predict concrete future actions. Traces that lead to good predictions are saved back into memory, so the library improves over time.
To score predictions, we use a temporal reward: since we can just wait and see what the user actually does, an LLM judge measures similarity between predicted and actual future actions. This lets us optimize both stages end-to-end through GRPO.
LongNAP significantly outperforms supervised finetuning (by 79%) and prompted baselines (by 39%). 17.1% pass@1, rising to 36.3% pass@20.
Citation
Cite This Work
@misc{shaikh2026learningactionpredictorshumancomputer,
title={Learning Next Action Predictors from Human-Computer Interaction},
author={Omar Shaikh and Valentin Teutschbein and Kanishk Gandhi and Yikun Chi and Nick Haber and Thomas Robinson and Nilam Ram and Byron Reeves and Sherry Yang and Michael S. Bernstein and Diyi Yang},
year={2026},
eprint={2603.05923},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2603.05923},
}